Spock Quick-Start Guide
Warning
This system was decommissioned on March 15, 2023 and is no longer online. Information here is presented as an archive and is no longer updated.
System Overview
Spock is an NCCS moderate-security system that contains similar hardware and software as the upcoming Frontier system. It is used as an early-access testbed for Center for Accelerated Application Readiness (CAAR) and Exascale Computing Project (ECP) teams as well as NCCS staff and our vendor partners. The system has 3 cabinets, each containing 12 compute nodes, for a total of 36 compute nodes.
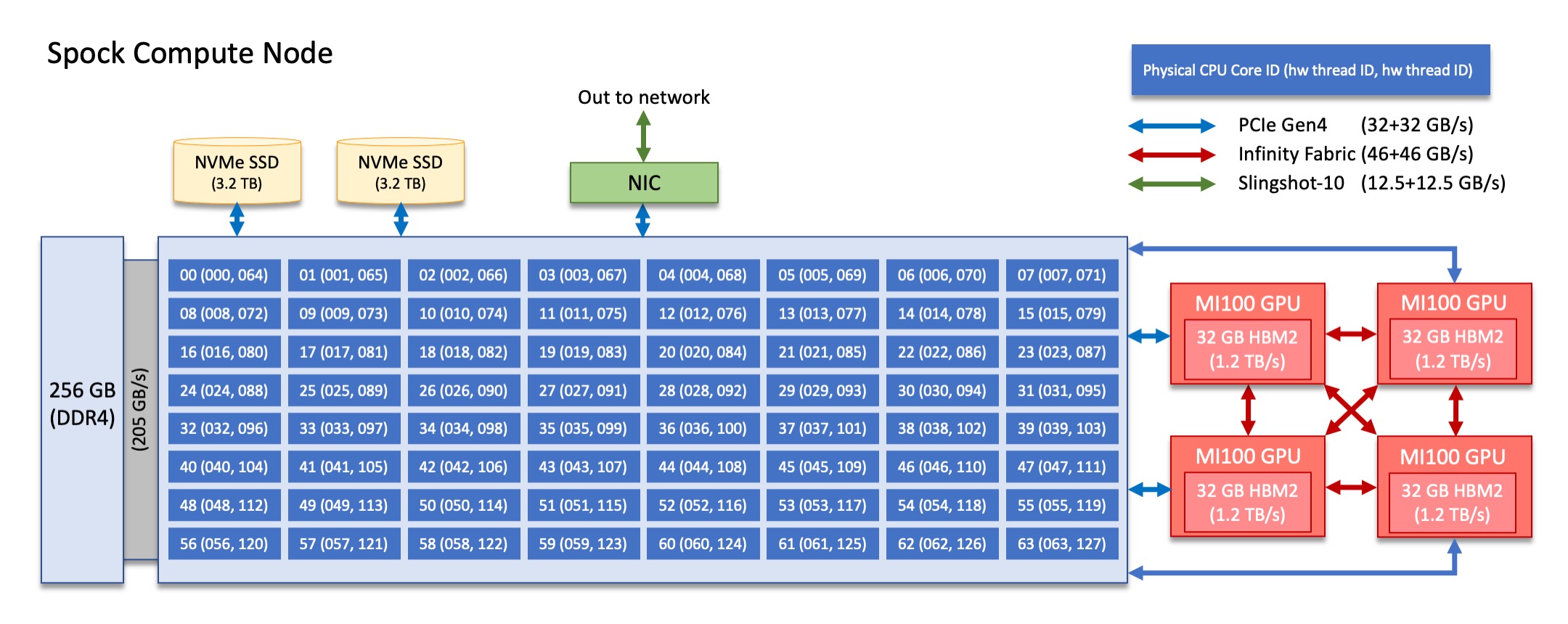
Spock Compute Nodes
Each Spock compute node consists of [1x] 64-core AMD EPYC 7662 “Rome” CPU (with 2 hardware threads per physical core) with access to 256 GB of DDR4 memory and connected to [4x] AMD MI100 GPUs. The CPU is connected to all GPUs via PCIe Gen4, allowing peak host-to-device (H2D) and device-to-host (D2H) data transfers of 32+32 GB/s. The GPUs are connected in an all-to-all arrangement via Infinity Fabric (xGMI), allowing for a peak device-to-device bandwidth of 46+46 GB/s. Each compute node also has [2x] 3.2 TB NVMe devices (SSDs) with sequential read and write speeds of 6900 MB/s and 4200 MB/s, respectively.
Note
The X+X GB/s values for bandwidths above represent bi-directional bandwidths. So, for example, the Infinity Fabric connecting any two GPUs allows peak data transfers of 46 GB/s in both directions simultaneously.
Note
There are 4 NUMA domains per node, that are defined as follows:
NUMA 0: hardware threads 000-015, 064-079 | GPU 0
NUMA 1: hardware threads 016-031, 080-095 | GPU 1
NUMA 2: hardware threads 032-047, 096-111 | GPU 2
NUMA 3: hardware threads 048-063, 112-127 | GPU 3
System Interconnect
The Spock nodes are connected with Slingshot-10 providing a node injection bandwidth of 12.5 GB/s.
File Systems
Spock is connected to an IBM Spectrum Scale™ filesystem providing 250 PB of storage capacity with a peak write speed of 2.5 TB/s. Spock also has access to the center-wide NFS-based filesystem (which provides user and project home areas). While Spock does not have direct access to the center’s Nearline archival storage system (Kronos) - for user and project archival storage - users can log in to the moderate DTNs to move data to/from Kronos or use the “OLCF Kronos” Globus collection. For more information on using Kronos, see the Kronos Nearline Archival Storage System section.
GPUs
Spock contains a total of 144 AMD MI100 GPUs. The AMD MI100 GPU has a peak performance of up to 11.5 TFLOPS in double-precision for modeling & simulation and up to 184.6 TFLOPS in half-precision for machine learning and data analytics. Each GPU contains 120 compute units (7680 stream processors) and 32 GB of high-bandwidth memory (HBM2) which can be accessed at speeds of up to 1.2 TB/s.
Connecting
To connect to Spock, ssh to spock.olcf.ornl.gov. For example:
$ ssh username@spock.olcf.ornl.gov
For more information on connecting to OLCF resources, see Connecting for the first time.
Data and Storage
For more detailed information about center-wide file systems and data archiving available on Spock, please refer to the pages on Data Storage and Transfers, but the two subsections below give a quick overview of NFS and GPFS storage spaces.
NFS
Area |
Path |
Type |
Permissions |
Quota |
Backups |
Purged |
Retention |
On Compute Nodes |
|---|---|---|---|---|---|---|---|---|
User Home |
|
NFS |
User set |
50 GB |
Yes |
No |
90 days |
Read-only |
Project Home |
|
NFS |
770 |
50 GB |
Yes |
No |
90 days |
Read-only |
GPFS
Area |
Path |
Type |
Permissions |
Quota |
Backups |
Purged |
Retention |
On Compute Nodes |
|---|---|---|---|---|---|---|---|---|
Member Work |
|
Spectrum Scale |
700 |
50 TB |
No |
90 days |
N/A |
Yes |
Project Work |
|
Spectrum Scale |
770 |
50 TB |
No |
90 days |
N/A |
Yes |
World Work |
|
Spectrum Scale |
775 |
50 TB |
No |
90 days |
N/A |
Yes |
Programming Environment
OLCF provides Spock users many pre-installed software packages and scientific libraries. To facilitate this, environment management tools are used to handle necessary changes to the shell.
Environment Modules (Lmod)
Environment modules are provided through Lmod, a Lua-based module system for
dynamically altering shell environments. By managing changes to the shell’s
environment variables (such as PATH, LD_LIBRARY_PATH, and
PKG_CONFIG_PATH), Lmod allows you to alter the software available in your
shell environment without the risk of creating package and version combinations
that cannot coexist in a single environment.
General Usage
The interface to Lmod is provided by the module command:
Command |
Description |
|---|---|
|
Shows a terse list of the currently loaded modules |
|
Shows a table of the currently available modules |
|
Shows help information about |
|
Shows the environment changes made by the |
|
Searches all possible modules according to |
|
Loads the given |
|
Adds |
|
Removes |
|
Unloads all modules |
|
Resets loaded modules to system defaults |
|
Reloads all currently loaded modules |
Searching for Modules
Modules with dependencies are only available when the underlying dependencies,
such as compiler families, are loaded. Thus, module avail will only display
modules that are compatible with the current state of the environment. To
search the entire hierarchy across all possible dependencies, the spider
sub-command can be used as summarized in the following table.
Command |
Description |
|---|---|
|
Shows the entire possible graph of modules |
|
Searches for modules named |
|
Searches for a specific version of |
|
Searches for modulefiles containing |
Compilers
Cray, AMD, and GCC compilers are provided through modules on Spock. The Cray
and AMD compilers are both based on LLVM/Clang. There are also system/OS
versions of both Clang and GCC available in /usr/bin. The table below lists
details about each of the module-provided compilers.
Note
It is highly recommended to use the Cray compiler wrappers (cc, CC, and ftn) whenever possible. See the next section for more details.
Vendor |
Programming Environment |
Compiler Module |
Language |
Compiler Wrapper |
Compiler |
|---|---|---|---|---|---|
Cray |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
AMD |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
|||
GCC |
|
|
C |
|
|
C++ |
|
|
|||
Fortran |
|
|
Cray Programming Environment and Compiler Wrappers
Cray provides PrgEnv-<compiler> modules (e.g., PrgEnv-cray) that load
compatible components of a specific compiler toolchain. The components include
the specified compiler as well as MPI, LibSci, and other libraries. Loading the
PrgEnv-<compiler> modules also defines a set of compiler wrappers for that
compiler toolchain that automatically add include paths and link in libraries
for Cray software. Compiler wrappers are provided for C (cc), C++ (CC),
and Fortran (ftn).
Note
Use the -craype-verbose flag to display the full include and link information used by the Cray compiler wrappers. This must be called on a file to see the full output (e.g., CC -craype-verbose test.cpp).
MPI
The MPI implementation available on Spock is Cray’s MPICH, which is “GPU-aware” so GPU buffers can be passed directly to MPI calls.
Compiling
This section covers how to compile for different programming models using the different compilers covered in the previous section.
MPI
Implementation |
Module |
Compiler |
Header Files & Linking |
|---|---|---|---|
Cray MPICH |
|
|
MPI header files and linking is built into the Cray compiler wrappers |
|
-L$(MPICH_DIR)/lib -lmpi-I$(MPICH_DIR)/include |
GPU-Aware MPI
To use GPU-aware Cray MPICH, there are currently some extra steps needed in addition to the table above, which depend on the compiler that is used.
1. Compiling with the Cray compiler wrappers, cc or CC
To use GPU-aware Cray MPICH with the Cray compiler wrappers, users must load specific modules, set some environment variables, and include appropriate headers and libraries. The following modules and environment variables must be set:
Note
Setting MPICH_SMP_SINGLE_COPY_MODE=CMA is required as a temporary workaround due to a known issue. Users should make a note of where they set this environment variable (if e.g., set in a script) since it should NOT be set once the known issue has been resolved.
module load craype-accel-amd-gfx908
module load PrgEnv-cray
module load rocm
## These must be set before running
export MPIR_CVAR_GPU_EAGER_DEVICE_MEM=0
export MPICH_GPU_SUPPORT_ENABLED=1
export MPICH_SMP_SINGLE_COPY_MODE=CMA
In addition, the following header files and libraries must be included:
-I${ROCM_PATH}/include
-L${ROCM_PATH}/lib -lamdhip64 -lhsa-runtime64
where the include path implies that #include <hip/hip_runtime.h> is included in the source file.
2. Compiling with hipcc
To use GPU-aware Cray MPICH with hipcc, users must load specific modules, set some environment variables, and include appropriate headers and libraries. The following modules and environment variables must be set:
module load craype-accel-amd-gfx908
module load PrgEnv-cray
module load rocm
## These must be set before running
export MPIR_CVAR_GPU_EAGER_DEVICE_MEM=0
export MPICH_GPU_SUPPORT_ENABLED=1
export MPICH_SMP_SINGLE_COPY_MODE=CMA
In addition, the following header files and libraries must be included:
-I${MPICH_DIR}/include
-L${MPICH_DIR}/lib -lmpi -L${CRAY_MPICH_ROOTDIR}/gtl/lib -lmpi_gtl_hsa
OpenMP
This section shows how to compile with OpenMP using the different compilers covered above.
Vendor |
Module |
Language |
Compiler |
OpenMP flag (CPU thread) |
|---|---|---|---|---|
Cray |
|
C, C++ |
ccCC |
|
Fortran |
|
-homp-fopenmp (alias) |
||
AMD |
|
C
C++
Fortran
|
$ROCM_PATH/llvm/bin/clang$ROCM_PATH/llvm/bin/clang++ROCM_PATH/llvm/bin/flang |
|
GCC |
|
C
C++
Fortran
|
$GCC_PATH/bin/gcc$GCC_PATH/bin/g++$GCC_PATH/bin/gfortran |
|
OpenMP GPU Offload
This section shows how to compile with OpenMP Offload using the different compilers covered above.
Note
Make sure the craype-accel-amd-gfx908 module is loaded when using OpenMP offload.
Vendor |
Module |
Language |
Compiler |
OpenMP flag (GPU) |
|---|---|---|---|---|
Cray |
|
C C++ |
ccCC |
|
Fortran |
|
-homp-fopenmp (alias) |
||
AMD |
|
C
C++
Fortran
|
$ROCM_PATH/llvm/bin/clang$ROCM_PATH/llvm/bin/clang++ROCM_PATH/llvm/bin/flanghipcc |
-fopenmp -target x86_64-pc-linux-gnu \-fopenmp-targets=amdgcn-amd-amdhsa \-Xopenmp-target=amdgcn-amd-amdhsa \-march=gfx908 |
HIP
This section shows how to compile HIP codes using the Cray compiler wrappers and hipcc compiler driver.
Note
Make sure the craype-accel-amd-gfx908 module is loaded when using HIP.
Compiler |
Compile/Link Flags, Header Files, and Libraries |
|---|---|
|
CFLAGS = -std=c++11 -D__HIP_ROCclr__ -D__HIP_ARCH_GFX908__=1 --rocm-path=${ROCM_PATH} --offload-arch=gfx908 -x hipLFLAGS = -std=c++11 -D__HIP_ROCclr__ --rocm-path=${ROCM_PATH}-I${HIP_PATH}/include-L${HIP_PATH}/lib -lamdhip64 |
|
Can be used directly to compile HIP source files.
To see what is being invoked within this compiler driver, issue the command,
hipcc --verbose |
Running Jobs
This section describes how to run programs on the Spock compute nodes, including a brief overview of Slurm and also how to map processes and threads to CPU cores and GPUs.
Slurm Workload Manager
Slurm is the workload manager used to interact with the compute nodes on Spock. In the following subsections, the most commonly used Slurm commands for submitting, running, and monitoring jobs will be covered, but users are encouraged to visit the official documentation and man pages for more information.
Batch Scheduler and Job Launcher
Slurm provides 3 ways of submitting and launching jobs on Spock’s compute nodes: batch scripts, interactive, and single-command. The Slurm commands associated with these methods are shown in the table below and examples of their use can be found in the related subsections.
|
Used to submit a batch script to allocate a Slurm job allocation. The script contains options preceded with
#SBATCH.(see Batch Scripts section below)
|
|
Used to allocate an interactive Slurm job allocation, where one or more job steps (i.e.,
srun commands) can then be launched on the allocated resources (i.e., nodes).(see Interactive Jobs section below)
|
|
Used to run a parallel job (job step) on the resources allocated with sbatch or
salloc.If necessary, srun will first create a resource allocation in which to run the parallel job(s).
(see Single Command section below)
|
Batch Scripts
A batch script can be used to submit a job to run on the compute nodes at a later time. In this case, stdout and stderr will be written to a file(s) that can be opened after the job completes. Here is an example of a simple batch script:
1#!/bin/bash
2#SBATCH -A <project_id>
3#SBATCH -J <job_name>
4#SBATCH -o %x-%j.out
5#SBATCH -t 00:05:00
6#SBATCH -p <partition>
7#SBATCH -N 2
8
9srun -n4 --ntasks-per-node=2 ./a.out
The Slurm submission options are preceded by #SBATCH, making them appear as
comments to a shell (since comments begin with #). Slurm will look for
submission options from the first line through the first non-comment line.
Options encountered after the first non-comment line will not be read by Slurm.
In the example script, the lines are:
Line |
Description |
|---|---|
1 |
[Optional] shell interpreter line |
2 |
OLCF project to charge |
3 |
Job name |
4 |
stdout file name ( |
5 |
Walltime requested ( |
6 |
Batch queue |
7 |
Number of compute nodes requested |
8 |
Blank line |
9 |
|
Interactive Jobs
To request an interactive job where multiple job steps (i.e., multiple srun
commands) can be launched on the allocated compute node(s), the salloc
command can be used:
$ salloc -A <project_id> -J <job_name> -t 00:05:00 -p <partition> -N 2
salloc: Granted job allocation 4258
salloc: Waiting for resource configuration
salloc: Nodes spock[10-11] are ready for job
$ srun -n 4 --ntasks-per-node=2 ./a.out
<output printed to terminal>
$ srun -n 2 --ntasks-per-node=1 ./a.out
<output printed to terminal>
Here, salloc is used to request an allocation of 2 MI100 compute nodes for
5 minutes. Once the resources become available, the user is granted access to
the compute nodes (spock10 and spock11 in this case) and can launch job
steps on them using srun.
Single Command (non-interactive)
$ srun -A <project_id> -t 00:05:00 -p <partition> -N 2 -n 4 --ntasks-per-node=2 ./a.out
<output printed to terminal>
The job name and output options have been removed since stdout/stderr are typically desired in the terminal window in this usage mode.
Common Slurm Submission Options
The table below summarizes commonly-used Slurm job submission options:
|
Project ID to charge |
|
Name of job |
|
Partition / batch queue |
|
Wall clock time < |
|
Number of compute nodes |
|
Standard output file name |
|
Standard error file name |
For more information about these and/or other options, please see the
sbatch man page.
Other Common Slurm Commands
The table below summarizes commonly-used Slurm commands:
|
Used to view partition and node information.
E.g., to view user-defined details about the caar queue:
sinfo -p caar -o "%15N %10D %10P %10a %10c %10z" |
|
Used to view job and job step information for jobs in the scheduling queue.
E.g., to see all jobs from a specific user:
squeue -l -u <user_id> |
|
Used to view accounting data for jobs and job steps in the job accounting log (currently in the queue or recently completed).
E.g., to see a list of specified information about all jobs submitted/run by a users since 1 PM on January 4, 2021:
sacct -u <username> -S 2021-01-04T13:00:00 -o "jobid%5,jobname%25,user%15,nodelist%20" -X |
|
Used to signal or cancel jobs or job steps.
E.g., to cancel a job:
scancel <jobid> |
|
Used to view or modify job configuration.
E.g., to place a job on hold:
scontrol hold <jobid> |
Slurm Compute Node Partitions
Spock’s compute nodes are separated into 2 Slurm partitions (queues): 1 for CAAR projects and 1 for ECP projects. Please see the tables below for details.
Note
If CAAR or ECP teams require a temporary exception to this policy, please email help@olcf.ornl.gov with your request and it will be given to the OLCF Resource Utilization Council (RUC) for review.
CAAR Partition
The CAAR partition consists of 24 total compute nodes. On a per-project basis, each user can have 1 running and 1 eligible job at a time, with no limit on the number of jobs submitted.
Number of Nodes |
Max Walltime |
|---|---|
1 - 4 |
3 hours |
5 - 16 |
1 hour |
ECP Partition
The ECP partition consists of 12 total compute nodes. On a per-project basis, each user can have 1 running and 1 eligible job at a time, with up to 5 jobs submitted.
Number of Nodes |
Max Walltime |
|---|---|
1 - 4 |
3 hours |
Process and Thread Mapping
This section describes how to map processes (e.g., MPI ranks) and process threads (e.g., OpenMP threads) to the CPUs and GPUs on Spock. The Spock Compute Nodes diagram will be helpful when reading this section to understand which hardware threads your processes and threads run on.
CPU Mapping
In this sub-section, a simple MPI+OpenMP “Hello, World” program (hello_mpi_omp) will be used to clarify the mappings. Slurm’s Interactive Jobs method was used to request an allocation of 1 compute node for these examples: salloc -A <project_id> -t 30 -p <parition> -N 1
The srun options used in this section are (see man srun for more information):
|
Request that
ncpus be allocated per process (default is 1).(
ncpus refers to hardware threads) |
|
In task layout, use the specified maximum number of threads per core
(default is 1; there are 2 hardware threads per physical CPU core).
|
|
Bind tasks to CPUs.
threads - Automatically generate masks binding tasks to threads.(Although this option is not explicitly used in these examples, it is the default CPU binding.)
|
Note
In the srun man page (and so the table above), threads refers to hardware threads.
2 MPI ranks - each with 2 OpenMP threads
In this example, the intent is to launch 2 MPI ranks, each of which spawn 2 OpenMP threads, and have all of the 4 OpenMP threads run on different physical CPU cores.
First (INCORRECT) attempt
To set the number of OpenMP threads spawned per MPI rank, the OMP_NUM_THREADS environment variable can be used. To set the number of MPI ranks launched, the srun flag -n can be used.
$ export OMP_NUM_THREADS=2
$ srun -n2 ./hello_mpi_omp | sort
WARNING: Requested total thread count and/or thread affinity may result in
oversubscription of available CPU resources! Performance may be degraded.
Explicitly set OMP_WAIT_POLICY=PASSIVE or ACTIVE to suppress this message.
Set CRAY_OMP_CHECK_AFFINITY=TRUE to print detailed thread-affinity messages.
WARNING: Requested total thread count and/or thread affinity may result in
oversubscription of available CPU resources! Performance may be degraded.
Explicitly set OMP_WAIT_POLICY=PASSIVE or ACTIVE to suppress this message.
Set CRAY_OMP_CHECK_AFFINITY=TRUE to print detailed thread-affinity messages.
MPI 000 - OMP 000 - HWT 000 - Node spock01
MPI 000 - OMP 001 - HWT 000 - Node spock01
MPI 001 - OMP 000 - HWT 016 - Node spock01
MPI 001 - OMP 001 - HWT 016 - Node spock01
The first thing to notice here is the WARNING about oversubscribing the available CPU cores. Also, the output shows each MPI rank did spawn 2 OpenMP threads, but both OpenMP threads ran on the same hardware thread (for a given MPI rank). This was not the intended behavior; each OpenMP thread was meant to run on its own physical CPU core.
Second (CORRECT) attempt
By default, each MPI rank is allocated only 1 hardware thread, so both OpenMP threads only have that 1 hardware thread to run on - hence the WARNING and undesired behavior. In order for each OpenMP thread to run on its own physical CPU core, each MPI rank should be given 2 hardware thread (-c 2) - since, by default, only 1 hardware thread per physical CPU core is enabled (this would need to be -c 4 if --threads-per-core=2 instead of the default of 1. The OpenMP threads will be mapped to unique physical CPU cores unless there are not enough physical CPU cores available, in which case the remaining OpenMP threads will share hardware threads and a WARNING will be issued as shown in the previous example.
$ export OMP_NUM_THREADS=2
$ srun -n2 -c2 ./hello_mpi_omp | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13
MPI 000 - OMP 001 - HWT 001 - Node spock13
MPI 001 - OMP 000 - HWT 016 - Node spock13
MPI 001 - OMP 001 - HWT 017 - Node spock13
Now the output shows that each OpenMP thread ran on (one of the hardware threads of) its own physical CPU cores. More specifically (see the Spock Compute Node diagram), OpenMP thread 000 of MPI rank 000 ran on hardware thread 000 (i.e., physical CPU core 00), OpenMP thread 001 of MPI rank 000 ran on hardware thread 001 (i.e., physical CPU core 01), OpenMP thread 000 of MPI rank 001 ran on hardware thread 016 (i.e., physical CPU core 16), and OpenMP thread 001 of MPI rank 001 ran on hardware thread 017 (i.e., physical CPU core 17) - as expected.
Note
There are many different ways users might choose to perform these mappings, so users are encouraged to clone the hello_mpi_omp program and test whether or not processes and threads are running where intended.
GPU Mapping
In this sub-section, an MPI+OpenMP+HIP “Hello, World” program (hello_jobstep) will be used to clarify the GPU mappings. Again, Slurm’s Interactive Jobs method was used to request an allocation of 2 compute node for these examples: salloc -A <project_id> -t 30 -p <parition> -N 2. The CPU mapping part of this example is very similar to the example used above in the CPU Mapping sub-section, so the focus here will be on the GPU mapping part.
The following srun options will be used in the examples below. See man srun for a complete list of options and more information.
|
Specify the number of GPUs required for the job on each task to be spawned in the job’s resource allocation. |
|
Binds each task to the GPU which is on the same NUMA domain as the CPU core the MPI rank is running on. |
|
Bind tasks to specific GPUs by setting GPU masks on tasks (or ranks) as specified where
|
|
Request that there are ntasks tasks invoked for every GPU. |
|
Specifies the distribution of MPI ranks across compute nodes, sockets (NUMA domains on Spock), and cores,
respectively. The default values are |
Note
In general, GPU mapping can be accomplished in different ways. For example, an application might map MPI ranks to GPUs programmatically within the code using, say, hipSetDevice. In this case, since all GPUs on a node are available to all MPI ranks on that node by default, there might not be a need to map to GPUs using Slurm (just do it in the code). However, in another application, there might be a reason to make only a subset of GPUs available to the MPI ranks on a node. It is this latter case that the following examples refer to.
Mapping 1 task per GPU
In the following examples, each MPI rank (and its OpenMP threads) will be mapped to a single GPU.
Example 1: 4 MPI ranks - each with 2 OpenMP threads and 1 GPU (single-node)
This example launches 4 MPI ranks (-n4), each with 2 physical CPU cores (-c2) to launch 2 OpenMP threads (OMP_NUM_THREADS=2) on. In addition, each MPI rank (and its 2 OpenMP threads) should have access to only 1 GPU. To accomplish the GPU mapping, two new srun options will be used:
--gpus-per-taskspecifies the number of GPUs required for the job on each task--gpu-bind=closestbinds each task to the GPU which is closest.
Note
To further clarify, --gpus-per-task does not actually bind GPUs to MPI ranks. It allocates GPUs to the job step. The --gpu-bind=closest is what actually maps a specific GPU to each rank; namely, the “closest” one, which is the GPU on the same NUMA domain as the CPU core the MPI rank is running on (see the Spock Compute Nodes section).
Note
Without these additional flags, all MPI ranks would have access to all GPUs (which is the default behavior).
$ export OMP_NUM_THREADS=2
$ srun -N1 -n4 -c2 --gpus-per-task=1 --gpu-bind=closest ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 000 - OMP 001 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 001 - OMP 001 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 002 - OMP 001 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 003 - OMP 001 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
The output contains different IDs associated with the GPUs so it is important to first describe these IDs before moving on. GPU_ID is the node-level (or global) GPU ID, which is labeled as one might expect from looking at a node diagram: 0, 1, 2, 3. RT_GPU_ID is the HIP runtime GPU ID, which can be thought of as each MPI rank’s local GPU ID numbering (with zero-based indexing). So in the output above, each MPI rank has access to 1 unique GPU - where MPI 000 has access to GPU 0, MPI 001 has access to GPU 1, etc., but all MPI ranks show a HIP runtime GPU ID of 0. The reason is that each MPI rank only “sees” one GPU and so the HIP runtime labels it as “0”, even though it might be global GPU ID 0, 1, 2, or 3. The GPU’s bus ID is included to definitively show that different GPUs are being used.
Here is a summary of the different GPU IDs reported by the example program:
GPU_IDis the node-level (or global) GPU ID read fromROCR_VISIBLE_DEVICES. If this environment variable is not set (either by the user or by Slurm), the value ofGPU_IDwill be set toN/A.RT_GPU_IDis the HIP runtime GPU ID (as reported from, sayhipGetDevice).Bus_IDis the physical bus ID associated with the GPUs. Comparing the bus IDs is meant to definitively show that different GPUs are being used.
So the job step (i.e., srun command) used above gave the desired output. Each MPI rank spawned 2 OpenMP threads and had access to a unique GPU. The --gpus-per-task=1 allocated 1 GPU for each MPI rank and the --gpu-bind=closest ensured that the closest GPU to each rank was the one used.
Example 2: 8 MPI ranks - each with 2 OpenMP threads and 1 GPU (multi-node)
This example will extend Example 1 to run on 2 nodes. As the output shows, it is a very straightforward exercise of changing the number of nodes to 2 (-N2) and the number of MPI ranks to 8 (-n8).
$ export OMP_NUM_THREADS=2
$ srun -N2 -n8 -c2 --gpus-per-task=1 --gpu-bind=closest ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 000 - OMP 001 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 001 - OMP 001 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 002 - OMP 001 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 003 - OMP 001 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 004 - OMP 000 - HWT 000 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 004 - OMP 001 - HWT 001 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 005 - OMP 000 - HWT 016 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 005 - OMP 001 - HWT 017 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 006 - OMP 000 - HWT 032 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 006 - OMP 001 - HWT 033 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 007 - OMP 000 - HWT 048 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 007 - OMP 001 - HWT 049 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
Example 3: 4 MPI ranks - each with 2 OpenMP threads and 1 *specific* GPU (single-node)
This example will be very similar to Example 1, but instead of using --gpu-bind=closest to map each MPI rank to the closest GPU, --gpu-bind=map_gpu will be used to map each MPI rank to a specific GPU. The map_gpu option takes a comma-separated list of GPU IDs to specify how the MPI ranks are mapped to GPUs, where the form of the comma-separated list is <gpu_id_for_task_0>, <gpu_id_for_task_1>,....
$ export OMP_NUM_THREADS=2
$ srun -N1 -n4 -c2 --gpus-per-task=1 --gpu-bind=map_gpu:0,1,2,3 ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 000 - OMP 001 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 001 - OMP 001 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 002 - OMP 001 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 003 - OMP 001 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
Here, the output is the same as the results from Example 1. This is because the 4 GPU IDs in the comma-separated list happen to specify the GPUs within the same NUMA domains that the MPI ranks are in. So MPI 000 is mapped to GPU 0, MPI 001 is mapped to GPU 1, etc.
While this level of control over mapping MPI ranks to GPUs might be useful for some applications, it is always important to consider the implication of the mapping. For example, if the order of the GPU IDs in the map_gpu option is reversed, the MPI ranks and the GPUs they are mapped to would be in different NUMA domains, which could potentially lead to poorer performance.
$ export OMP_NUM_THREADS=2
$ srun -N1 -n4 -c2 --gpus-per-task=1 --gpu-bind=map_gpu:3,2,1,0 ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 000 - OMP 001 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 001 - OMP 001 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 001 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 003 - OMP 001 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
Here, notice that MPI 000 now maps to GPU 3, MPI 001 maps to GPU 2, etc., so the MPI ranks are not in the same NUMA domains as the GPUs they are mapped to.
Note
Again, this particular example would NOT be a very good mapping of GPUs to MPI ranks though. E.g., notice that MPI rank 000 is running on NUMA node 0, whereas GPU 3 is on NUMA node 3. Again, see the Spock Compute Nodes section for NUMA descriptions.
Example 4: 8 MPI ranks - each with 2 OpenMP threads and 1 *specific* GPU (multi-node)
Extending Examples 2 and 3 to run on 2 nodes is also a straightforward exercise by changing the number of nodes to 2 (-N2) and the number of MPI ranks to 8 (-n8).
$ export OMP_NUM_THREADS=2
$ srun -N2 -n8 -c2 --gpus-per-task=1 --gpu-bind=map_gpu:0,1,2,3 ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 000 - OMP 001 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 001 - OMP 001 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 002 - OMP 001 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 003 - OMP 001 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 004 - OMP 000 - HWT 000 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 004 - OMP 001 - HWT 001 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 005 - OMP 000 - HWT 016 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 005 - OMP 001 - HWT 017 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 006 - OMP 000 - HWT 032 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 006 - OMP 001 - HWT 033 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 007 - OMP 000 - HWT 048 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 007 - OMP 001 - HWT 049 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
Mapping multiple MPI ranks to a single GPU
In the following examples, 2 MPI ranks will be mapped to 1 GPU. For the sake of brevity, OMP_NUM_THREADS will be set to 1, so -c1 will be used unless otherwise specified.
Note
On AMD’s MI100 GPUs, multi-process service (MPS) is not needed since multiple MPI ranks per GPU is supported natively.
Example 5: 8 MPI ranks - where 2 ranks share a GPU (round-robin, single-node)
This example launches 8 MPI ranks (-n8), each with 1 physical CPU core (-c1) to launch 1 OpenMP thread (OMP_NUM_THREADS=1) on. The MPI ranks will be assigned to GPUs in a round-robin fashion so that each of the 4 GPUs on the node are shared by 2 MPI ranks. To accomplish this GPU mapping, a new srun option will be used:
--ntasks-per-gpuspecifies the number of MPI ranks that will share access to a GPU.
$ export OMP_NUM_THREADS=1
$ srun -N1 -n8 -c1 --ntasks-per-gpu=2 --gpu-bind=closest ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 000 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 004 - OMP 000 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 005 - OMP 000 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 006 - OMP 000 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 007 - OMP 000 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
The output shows the round-robin (cyclic) distribution of MPI ranks to GPUs. In fact, it is a round-robin distribution of MPI ranks to NUMA domains (the default distribution). The GPU mapping is a consequence of where the MPI ranks are distributed; --gpu-bind=closest simply maps the GPU in a NUMA domain to the MPI ranks in the same NUMA domain.
Example 6: 16 MPI ranks - where 2 ranks share a GPU (round-robin, multi-node)
This example is an extension of Example 5 to run on 2 nodes.
Warning
This example requires a workaround to run as expected. --ntasks-per-gpu=2 does not force MPI ranks 008-015 to run on the second node, so the number of physical CPU cores per MPI rank is increased to 8 (-c8) to force the desired behavior due to the constraint of the number of physical CPU cores (64) on a node.
$ export OMP_NUM_THREADS=1
$ srun -N2 -n16 -c8 --ntasks-per-gpu=2 --gpu-bind=closest ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 005 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 018 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 002 - OMP 000 - HWT 032 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 003 - OMP 000 - HWT 050 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 004 - OMP 000 - HWT 010 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 005 - OMP 000 - HWT 026 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 006 - OMP 000 - HWT 040 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 007 - OMP 000 - HWT 059 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 008 - OMP 000 - HWT 003 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 009 - OMP 000 - HWT 016 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 010 - OMP 000 - HWT 032 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 011 - OMP 000 - HWT 048 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 012 - OMP 000 - HWT 008 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 013 - OMP 000 - HWT 024 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 014 - OMP 000 - HWT 042 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 015 - OMP 000 - HWT 056 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
Example 7: 8 MPI ranks - where 2 ranks share a GPU (packed, single-node)
This example launches 8 MPI ranks (-n8), each with 8 physical CPU cores (-c8) to launch 1 OpenMP thread (OMP_NUM_THREADS=1) on. The MPI ranks will be assigned to GPUs in a packed fashion so that each of the 4 GPUs on the node are shared by 2 MPI ranks. Similar to Example 5, -ntasks-per-gpu=2 will be used, but a new srun flag will be used to change the default round-robin (cyclic) distribution of MPI ranks across NUMA domains:
--distribution=<value>:[<value>]:[<value>]specifies the distribution of MPI ranks across compute nodes, sockets (NUMA domains on Spock), and cores, respectively. The default values areblock:cyclic:cyclic, which is where thecyclicassignment comes from in the previous examples.
Note
In the job step for this example, --distribution=*:block is used, where * represents the default value of block for the distribution of MPI ranks across compute nodes and the distribution of MPI ranks across NUMA domains has been changed to block from its default value of cyclic.
Note
Because the distribution across NUMA domains has been changed to a “packed” (block) configuration, caution must be taken to ensure MPI ranks end up in the NUMA domains where the GPUs they intend to be mapped to are located. To accomplish this, the number of physical CPU cores assigned to an MPI rank was increased - in this case to 8. Doing so ensures that only 2 MPI ranks can fit into a single NUMA domain. If the value of -c was left at 1, all 8 MPI ranks would be “packed” into the first NUMA domain, where the “closest” GPU would be GPU 0 - the only GPU in that NUMA domain.
Notice that this is not a workaround like in Example 6, but a requirement due to the block distribution of MPI ranks across NUMA domains.
$ export OMP_NUM_THREADS=1
$ srun -N1 -n8 -c8 --ntasks-per-gpu=2 --gpu-bind=closest --distribution=*:block ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 001 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 008 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 002 - OMP 000 - HWT 016 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 003 - OMP 000 - HWT 024 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 004 - OMP 000 - HWT 035 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 005 - OMP 000 - HWT 043 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 006 - OMP 000 - HWT 049 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 007 - OMP 000 - HWT 057 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
The overall effect of using --distribution=*:block and increasing the number of physical CPU cores available to each MPI rank is to place the first two MPI ranks in NUMA 0 with GPU 0, the next two MPI ranks in NUMA 1 with GPU 1, and so on.
Example 8: 16 MPI ranks - where 2 ranks share a GPU (packed, multi-node)
This example is an extension of Example 7 to use 2 compute nodes. With the appropriate changes put in place in Example 7, it is a straightforward exercise to change to using 2 nodes (-N2) and 16 MPI ranks (-n16).
$ export OMP_NUM_THREADS=1
$ srun -N2 -n16 -c8 --ntasks-per-gpu=2 --gpu-bind=closest --distribution=*:block ./hello_jobstep | sort
MPI 000 - OMP 000 - HWT 005 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 001 - OMP 000 - HWT 008 - Node spock13 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 002 - OMP 000 - HWT 017 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 003 - OMP 000 - HWT 026 - Node spock13 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 004 - OMP 000 - HWT 033 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 005 - OMP 000 - HWT 041 - Node spock13 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 006 - OMP 000 - HWT 048 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 007 - OMP 000 - HWT 057 - Node spock13 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 008 - OMP 000 - HWT 002 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 009 - OMP 000 - HWT 011 - Node spock14 - RT_GPU_ID 0 - GPU_ID 0 - Bus_ID c9
MPI 010 - OMP 000 - HWT 016 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 011 - OMP 000 - HWT 026 - Node spock14 - RT_GPU_ID 0 - GPU_ID 1 - Bus_ID 87
MPI 012 - OMP 000 - HWT 033 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 013 - OMP 000 - HWT 041 - Node spock14 - RT_GPU_ID 0 - GPU_ID 2 - Bus_ID 48
MPI 014 - OMP 000 - HWT 054 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
MPI 015 - OMP 000 - HWT 063 - Node spock14 - RT_GPU_ID 0 - GPU_ID 3 - Bus_ID 09
Multiple GPUs per MPI rank
As mentioned previously, all GPUs are accessible by all MPI ranks by default, so it is possible to programatically map any combination of MPI ranks to GPUs. However, there is currently no way to use Slurm to map multiple GPUs to a single MPI rank. If this functionality is needed for an application, please submit a ticket by emailing help@olcf.ornl.gov.
Note
There are many different ways users might choose to perform these mappings, so users are encouraged to clone the hello_jobstep program and test whether or not processes and threads are running where intended.
NVMe Usage
Each Spock compute node has [2x] 3.2 TB NVMe devices (SSDs) with a peak sequential performance of 6900 MB/s (read) and 4200 MB/s (write). To use the NVMe, users must request access during job allocation using the -C nvme option to sbatch, salloc, or srun. Once the devices have been granted to a job, users can access them at /mnt/bb/<userid>. Users are responsible for moving data to/from the NVMe before/after their jobs. Here is a simple example script:
#!/bin/bash
#SBATCH -A <projid>
#SBATCH -J nvme_test
#SBATCH -o %x-%j.out
#SBATCH -t 00:05:00
#SBATCH -p batch
#SBATCH -N 1
#SBATCH -C nvme
date
# Change directory to user scratch space (GPFS)
cd /gpfs/alpine/<projid>/scratch/<userid>
echo " "
echo "*****ORIGINAL FILE*****"
cat test.txt
echo "***********************"
# Move file from GPFS to SSD
mv test.txt /mnt/bb/<userid>
# Edit file from compute node
srun -n1 hostname >> /mnt/bb/<userid>/test.txt
# Move file from SSD back to GPFS
mv /mnt/bb/<userid>/test.txt .
echo " "
echo "*****UPDATED FILE******"
cat test.txt
echo "***********************"
And here is the output from the script:
$ cat nvme_test-<jobid>.out
Mon May 17 12:28:18 EDT 2021
*****ORIGINAL FILE*****
This is my file. There are many like it but this one is mine.
***********************
*****UPDATED FILE******
This is my file. There are many like it but this one is mine.
spock25
***********************
Getting Help
If you have problems or need helping running on Spock, please submit a ticket by emailing help@olcf.ornl.gov.